Simplified Lambda Architecture
Posted on Tue 01 September 2015
Preamble
In 2015 while working at Flickr we needed to build a new database architecture that combined large-scale realtime and offline compute into a single database. Below is an excerpt from our original writeup here; you can try it for yourself here.
Introduction
Flickr’s Magic View takes the hassle out of organizing your own photos by applying our cutting-edge, computer-vision technology to automatically categorize photos in your photostream and present them in a seamless view based on the content in the photos. This all happens in real-time - as soon as a photo is uploaded, it is categorized and placed into the Magic View.
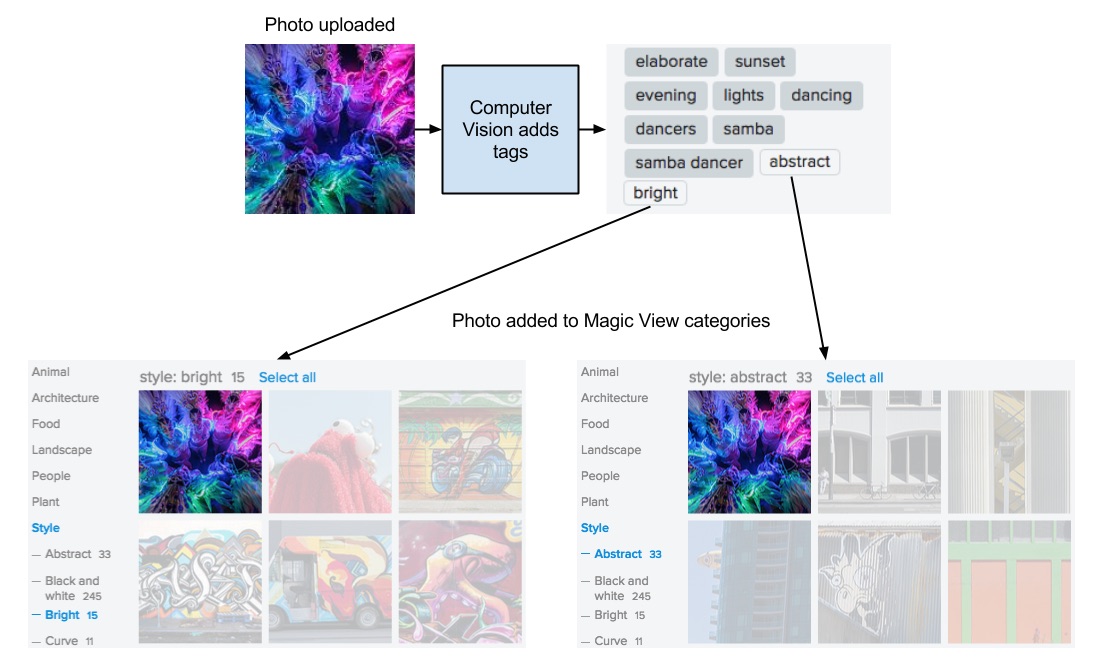
The Challenge
Our computational footprint made it easy to create per-user Magic View categories for over 12 billion images on Flickr; however, we also needed to combine this with updating the categories with the the tens of millions of tags generated from photos as they are uploaded in real-time. Ideally, the system has to allow us to efficiently but separately manage the bulk and real-time data that only computes the final state when requested. We turned to Yahoo’s Hadoop stack to find a way to build this at the massive scale we needed.
Our Solution
Powered by Apache HBase, we developed a new scheme to fuse results from bulk and real-time aggregations. Using a single table in HBase, we are able to independently update and manage the bulk and real-time data in the system while always being able to provide a consistent, correct result.
We believe that this solution is a novel simplification of what is sometimes known as Lambda Architecture. We improve it by simplifying some of its complicated components making maintenance and development easier.
Lambda Architecture
Existing approach
We’ll start with Nathan Marz’s book, ‘Big Data’, which proposes the database concept of ‘Lambda Architecture’. In his analysis, he states that a database query can be represented as a function - Query - which operates on all the data:
result = Query(data)
The core of the Lambda architecture allows for separately maintained real-time and bulk databases. Minimizing the number of sacrifices needed to be made but maintaining the goal of operating on all available data, the equation is now expressed as:
result = Combiner(Query(real-time data) + Query(bulk data))
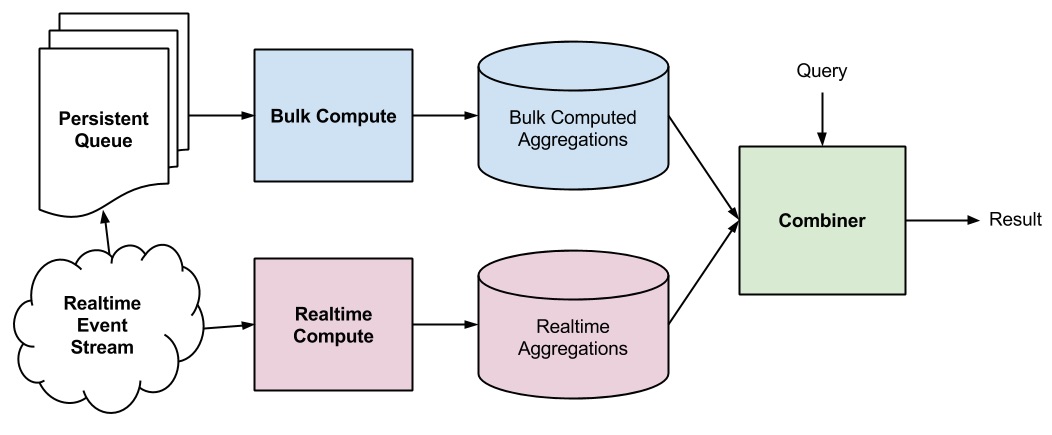
This equation is shown graphically in the figure above. The real-time and bulk compute subsystem write to independent databases, which could be totally different systems. When dealing with a high volume of realtime data, the operational advantage here can be significant - there’s no need to have the expense of combining it with bulk data every time an event comes in.
Concerns around this approach center on the complicated nature of the Combiner function - there is the developer and systems cost from the need to maintain two separate databases, the differing latencies of querying both sides and then the mechanics of merging the result.
Our Approach
We addressed the complications of the Combiner by instead using a single database to store the real-time and bulk data. A Combiner is still required to compute a final result:
result = Combiner(Query(data))
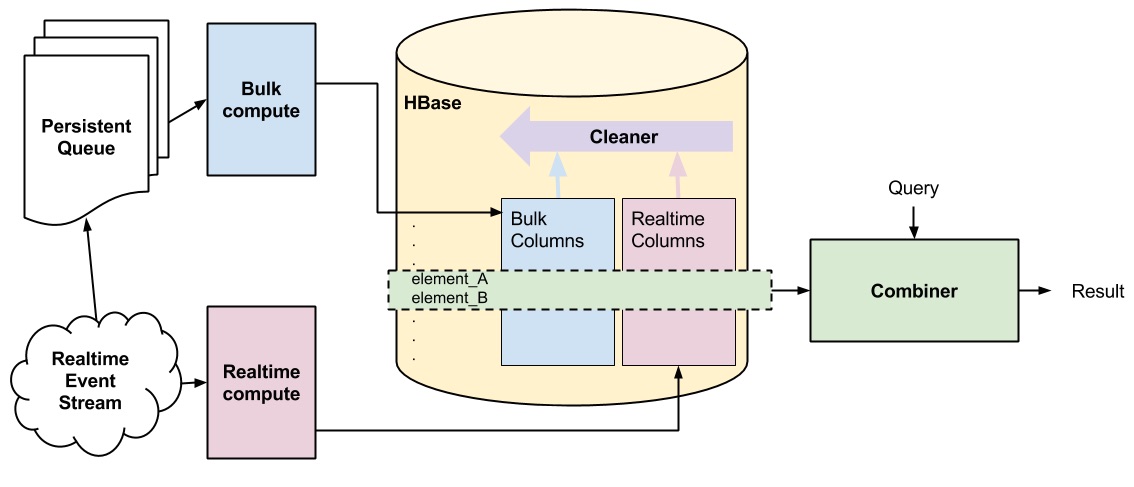
How was this achieved? We implement our simplified Lambda architecture in HBase by giving each row two sets of columns - real-time and bulk - which are managed independently by the real-time subsystem (Storm and Java) and the bulk compute subsystem (Pig Latin and Oozie). It’s worth noting that FiloDb takes a similar approach - but since we only require the latest version of the data, our implementation is simpler.
The combiner stage is abstracted into a single Java process running on its own hardware which computes on the data in HBase and pushes the photostream tag aggregations to a cache for serving.
The Combiner and Cleaner
When reading a single row of data from HBase, we need to combine the data from the real-time and the bulk columns. If only the bulk or real-time data exists, then selecting the data is obvious. If both bulk and realtime data exists, we always pick real-time. This seems reasonable, but causes a subtle problem.
Let’s say a photos computer vision tags are added via real-time compute - there is no bulk data. Later on, we recompute all available photos using a new version of the computer vision tagging, and load this data (including this photo) via a bulk load. Even though the newer data exists in the bulk column, we can’t get to it because the combiner will only read the real-time column. We solve this by running the Cleaner process on all the data in HBase after we do a bulk load.
The Cleaner simply visits each row and sees if the HBase timestamp for the real-time data is older than the bulk load. If it is, then we delete the real-time data for that row since it’s already captured in the bulk columns. This way the results of the bulk compute aren’t ‘published’ until the cleaner has run.
Press
2015-09-03: The Next Web The Yahoo Behind Fresh Deep Learning Approaches at Flickr